Journey to PMD 7
This blog post talks about the lengthy journey to PMD 7 and gives some insights. And it contains my personal opinion on what could have been done better.
PMD 7 release
Now, the PMD 7 release is about one month in the past. Time to look back. Maybe first of all, some numbers. After one month, the download count on the binary distribution 7.0.0 on GitHub releases: 24,977. And on sourceforge: 283. If we look at maven central, we see that pmd-java 7.0.0 has been downloaded 4,097 times.
So, it is being used at least. Note, that the numbers are difficult to interpret - they don’t correspond to actual users. In a CI environment, PMD might be downloaded for every run. For comparison, here are the numbers of the older releases:
- pmd-dist-7.0.0-rc4-bin.zip: 125,160 (GitHub), 1,418 (Sourceforge)
- pmd-bin-6.55.0.zip: 235,410 (GitHub), 808 (Sourceforge)
- net.sourceforge.pmd:pmd-java:7.0.0-rc4: 23,177 (central, last month)
- net.sourceforge.pmd:pmd-java:6.55.0: 362,726 (central, last month)
The numbers from sourceforge can probably be ignored, they are insignificant small. The reason, why pmd-java 6.55.0 is so much more used is probably, because it is the default version of the maven-pmd-plugin. But the new version of maven-pmd-plugin 3.22.0 released this week uses by default PMD 7.0.0, so we can expect the numbers to go up.
How much an open source software is used, is often a blind spot. It’s freely available, you don’t need to register and often it is downloaded automatically by build tools.
Another metric might be, how many issues are opened. This is shown on GitHub Insights. For the last month we have:
- 22 new issues
- 86 closed issues
Enough numbers. Let’s go on to the beginning of PMD 7.
How it started
The major version before 7, PMD 6, was released end of 2017. The development of PMD 7 started about half a year later in June 2018 with commit 48d54b0a. This happened in a separate branch. June 2018 - this is almost 6 years ago. That means, that PMD 7 development actually took 6 years… crazy.
We had many ideas, and tried to sort them, using the wiki (see e.g. PMD 7.0.0). And it was a real challenge to keep track of the status during these 6 years. So, the wiki is outdated. Maybe I’m cleaning this up at some point and move this page into a archived section of the wiki. Yes, cleaning up is really required. We also have old roadmap documents…
During the 6 years of development, we released minor versions of PMD 6 almost every month. PMD 6.55.0 was the last release in February 2023. Then the effort started to finally wrap up PMD 7 and finished, what could be finished and post-pone the rest. This was not easy, as the status was often not so clear. Some ideas were started, but only half-way and not finished.
While not everything that was originally planned could be finished, still an amazing bunch of work has been done.
Why did it take so long? Did it take long?
So, why did it take so long after all? 6 years, that’s a very long time. You definitely need a lot of perseverance. Looking at the durations of previous major releases, I found these numbers:
| Major Version | Release Date | Duration |
|---|---|---|
| PMD 1.0 | 2002-11-04 | 5 months after first commit |
| PMD 2.0 | 2004-10-19 | 2 years |
| PMD 3.0 | 2005-03-23 | 5 months |
| PMD 4.0 | 2007-07-20 | 2 years and 4 months |
| PMD 5.0.0 | 2012-05-01 | 4 years and 9 months |
| PMD 6.0.0 | 2017-12-15 | 5 years and 7 months |
| PMD 7.0.0 | 2024-03-22 | 6 years and 3 months |
Indeed, this is till now the longest duration for a major release of PMD. It seems, that since PMD 4, the duration is always increasing.
So why did it take so long? First have a look at the timeline:
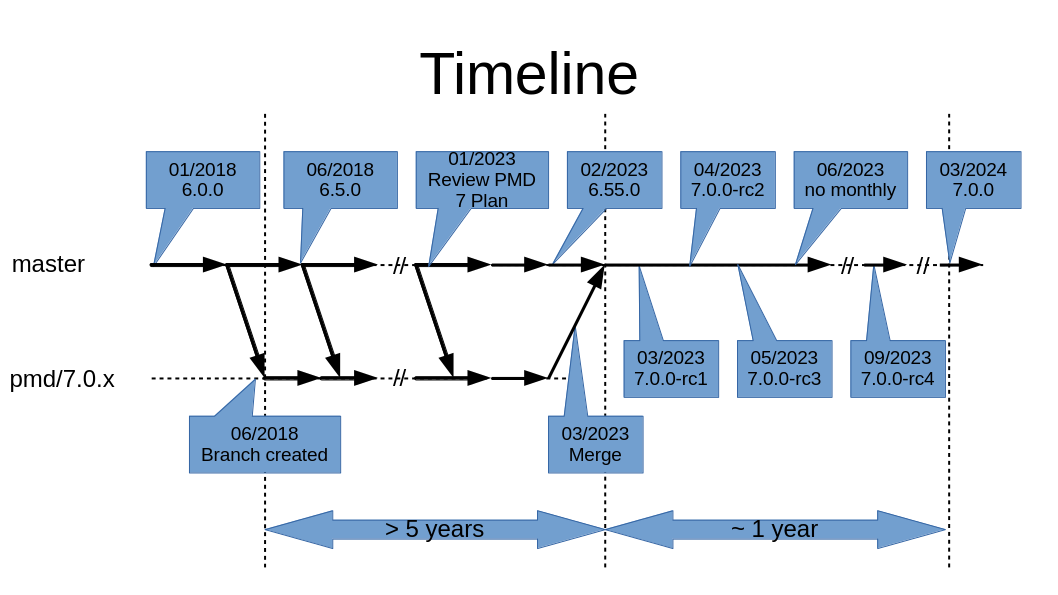
Here are maybe some reasons or an attempt to give some explanations…
-
There is only so much time available in one day. We had very ambitious plans at the beginning. Since PMD 6, which was also a long effort, was done, we were enthusiastic about the next version. Everything seemed possible.
-
For the most part, the work was only done by 2 or 3 persons (the “core team”). And this was done mostly in spare time (for me it was around 6% paid hours). And considering this, this is spectacular.
-
There were some other bigger contributions, like Apex Parser or Antlr support. While this was not done by the core team, these contributions still take time to understand, review and integrate.
-
The development for PMD 7 happened on a separate branch. In parallel, we still worked on PMD 6 and released almost every month a new minor version with bugfixes and smaller features.
-
The separate branch is a shiny thing: it feels a bit like greenfield development. You don’t need to fear to break something, because “it is just a branch”. Production-readiness is deferred. While this is maybe good for developing new features faster, it comes with a cost: We merged regularly from our main branch into the PMD 7 branch. The more the branches diverged, the more expensive this merging became. Additionally, this results in a more “interesting” git history, as the history is now non-linear. But that’s true for merging in general.
-
While I’m happy for contributions, every outside contribution takes time, even if it is as small as a single line fix. You need to react, respond, understand the original problem that is supposed to fix, verify that it is fixed (if it is a single line fix, then a unit test is missing), maybe explain, and so on.
-
Since the development of PMD 7 took so long, it was difficult to keep track of the status and progress we made. The status was spread in issues, wiki pages, meeting notes. There was no clear progress tracking, so the finish line was not clear and I guess it also moved. This is especially difficult for motivation.
-
Sometimes, we also had some massive pull requests. These are very challenging in reviewing, as they cost massive time to grasp, understand - and they make it difficult to update the progress, because the big PRs most likely takle multiple tasks at once, but maybe not completely.
-
Then this is not only about PMD itself. There is a small niche software ecosystem around it: all the plugins, build tools, continuous integration, build infrastructure. To name some: maven-pmd-plugin, pmd-eclipse-plugin, pmd-github-action, pmd-regression-tester, vscode-apex-pmd. So, there are happening many things in parallel.
Lessons learned?
So, what can we learn from this? What can we make better the next time?
I guess, that many things happening in parallel can’t be avoided. The world is spinning and not waiting for us. E.g. new Java versions are released, new Eclipse versions are released. But what can be avoided is, that we develop two versions in parallel. So, the next time I guess, I would try to avoid branching or try harder to avoid it. Once you branch, you often have doubled the effort: you also want to have a CI for the branch, which means, the scripts need to be maintained for both branches. You want to merge often and the more the branches diverge, the more difficult this becomes. We have seen this in the last one or two years of the branch. And because of this, I guess, we also hesitated to move classes around, rename this or that, because that would have created many difficult merge conflicts. Also, having a branch might make you think you can take a shortcut and disable some (unit) tests, while you change stuff. After all, this is just a branch and the release is far away. This is very dangerous, because that means, that the branch is not always ready. So, point one is: don’t branch.
We were also trying to keep backwards compatibility. Which is a good thing on the one hand. But at some point, I wondered: why did we create a branch anyway? It felt a bit like we were even trying to keep the branch still compatible. Maybe to avoid merge conflicts? Sometimes, new ideas were also backported to PMD 6, so that the new API could already be used and it would be less a effort in the end to migrate to PMD 7. But was creating the branch in the first place not done, so that we could break compatibility? I hope I learn for the next major release how to evolve and refactor software in a way, that keeps compatibility, while developing on the main branch. So, the point here is: learn to refactor in a compatible way. I’m not sure, whether this would have been possible all the time, but I think it’s worth to learn this. And my effort with pmd-compat6 showed, how much is possible in terms of compatibility. It’s kind of a hack, but it makes it possible to use PMD 7 with maven-pmd-plugin, that expects PMD 6 API.
The other point is deprecating API endpoints. This is good practices and we did it. But sometimes, we deprecated methods before the alternative was available. And then it happened, that the alternative was never finished. Very bad. IMHO, we should only deprecate things, after the alternative is ready to use. At the same time, all code should immediately use the alternative, so that the deprecated methods are only left in for compatibility - and could be easily removed in the next major version without the need to develop the alternative first - because it already exists. Of course, I guess, there are exceptions: If we deprecate something without a planned replacement, then there is no alternative. But then, this deprecated method should be used at all anymore - otherwise we need an alternative.
A variant, that should be used with care only, is the so-called “TODO development”. That means, instead of actually implementing and finishing things, you leave a couple of TODO comments behind. This adds up to the difficulty of keeping track of what is done and what is left to do. In other words, you should keep track of your TODO comments. This requires some discipline. Maybe a TODO comment means, this code is just not finished. Or it refers to another feature, that might be better described in its own.
The last point is the size. If you look at the Release Notes of PMD 7 this is ridiculous big. Of course, this is a side effect of 6 years. So, next time, we should try to release smaller features and more often. This means, I need to learn how to divide a feature properly in smaller parts that can be shipped in smaller units than a major version. I’m not sure, this is always possible, but that’s maybe an interesting challenge. E.g. changing the AST of Java in an incompatible way might mean, that PMD ships two versions of the AST and rules can decide whether to use the new version or the old compatible version. Sounds like feature toggle? Maybe, but anyway, that would be an interesting challenge. Shipping such changes earlier also gives all others a smoother time to adapt. Maybe every incompatible change should be first delivered as a new feature, that can be used as an opt-in. This approach might mean more effort, but creating a branch also doesn’t seem to help to deliver faster.
Future
In summary, what do I want to change now? For compatibility checks, we definitely need to add something like japicmp, because compatibility is important and if there is a tool, that helps us avoiding problems, then we have to use it. Compatibility is important, because it helps in adopting a new version without the need to follow a big migration guide.
Luckily, this is taken care of with version 7.1.0: Issue #494 is done.
I definitely want to try to avoid creating a branch for PMD 8. Ideally, we would create a new major version earlier and all what needs to be done for preparing a major version is to remove all deprecated API. Because the alternative API is already in place. Ok, in reality, this is probably too idealistic, but let’s try.
Maybe there is also more automation we can use. Like automated release notes? I’m still skeptical about this one, but who knows?
In general, there are still a couple of things to do and that can be tackled now, given the big PMD 7 release is done. These are
-
Improved rule descriptions. There is a lot, that can be improved to better explain why the code, that violates a given rule is exactly a problem. And what are possible remediations. Rules are organized into categories since PMD 6, but there might be other categories that could make sense to group rules. Implementing something like tagging would open up the opportunity for better finding rules that make sense for your project at hand. Given that we have more than 400 rules in total now, this is probably helpful. Another idea is, to have some kind of online ruleset editor, where you can drag & drop the rules you want including any specific configuration and then export your ruleset. That would make it easier to create a custom ruleset, as we recommend in Best Practices: Choose the rules that are right for you.
-
Speaking of documentation: There is a lot missing or old docs around roadmap, ideas, future plans, etc. It would also be beneficial to have some kind of overview of the architecture and some more explaining of how PMD works in the inside as part of developer documentation. Some of the documentation is also in the wiki, which would need to be moved. The same applies for governance and community docs, like: Who is deciding, when is a release ready, how to become a member, etc.
-
CI builds: These are currently a big block and if they fail, you always need to look at the logs to figure out, why it is failing. If these were more fine-grained, it would be one look to see that it failed e.g. while deploying the documentation or while running regression tests etc. The regression test results are currently not directly visible, which should be improved again to deploy them to some static site hosting. Having the CI build split up also provides the opportunity to parallelize the builds to speed them up. And maybe provide a nightly pre-release on GitHub as well.
So far, these points are all byproducts. But as we all love new features, maybe the following can be tackled?
-
PMD is missing solutions for multi file analysis, metrics reporting, data flow analysis and control flow analysis. For Dataflow there is some part done in Java, but this could be extended. And multi files analysis is often a key point, as you want to follow the data/control flow through your application. If PMD could look at all files in your application, there will also be more interesting metrics possible, like the size of a class in comparison to the average size of all classes in the application. Most likely, this requires some kind of multi pass analysis with one pass to gather information and the next pass to analyze this information. Right now, PMD analyzes file by file.
-
Kotlin AST: We could try to create a more abstract AST than what we currently have. This is basically the discussion Parse Tree vs. Abstract Syntax Tree. With Antlr, we just get the parse tree after having parsed the Kotlin source and another step is required to translate this parse tree into an abstract syntax tree with real nodes that can have real attributes. The interesting part about this is, whether we can keep compatibility there.
-
With more than 10 supported languages, the binary package of PMD is very big. Currently it is 62m big… which is a lot. Most of the users probably use only 1 or 2 languages. So maybe, it’s time to rethink the packaging of PMD. We have also no real insight, how much PMD is used. Adding some telemetry would be interesting, but raises another bunch of challenges.
-
Another idea is a “PMD Playground” in the web. Maybe a bit similar like the online versions of japicmp or the sandbox that is available on The Java Version Almanac. That would help in trying whether PMD is a good fit for a project or not without getting too involved already. It might also be helpful in reproducing false positives or false negatives of our rules. A more sophisticated implementation could store a workspace and provide a shareable link, like the ESLint Playground or any other javascript tooling like JSFiddle.
Comments
No comments yet.Leave a comment
Your email address will not be published. Required fields are marked *. All comments are held for moderation to avoid spam and abuse.